


 Document understanding (part 2)
Document understanding (part 2)
Actions
Document understanding (part 2)
Document understanding using deep learning techniques
part 2
Object Detection
Convolutional neural networks
The first convolutional neural networks (CNN) are introduced by Kunihiko Fukushima, Neocognitron in 1980 and Yann LeCun, Patrick Hafnner, Leon Bottou, Yoshua Bengio, “Object Recognition with Gradient-based Learning”, LeNet-5 in 1998. The name CNN comes from one of the most important operations in the network, which is the convolution. The convolution is performed on the input data with the use of a kernel to produce a feature map. It is executed by sliding the filter over the input. At every location, matrix multiplication is performed and sums the result onto the feature map. Convolutional neural nets have revolutionized speech and object detection. A CNN leverages three important fundaments as sparse connectivity, shared parameters and invariance to translation. Sparse weights refer to the reduced number of parameters, parameter sharing is the parameter usage for more than one function, making the parameters significantly computationally efficient. The invariance to translation means that if the input translates to some extent, the output changes in the same way. Among the very successful methods for object detection of the main focus in AI, communities are Faster R-CNN, RPN, Mask-RCNN, FCN. Faster R-CNN with RPN was proposed by Shaoqing Ren, Kaiming He, R. Girshick and Jian Sun in a very popular paper on “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”. “Mask R-CNN”, proposed by Kaiming He, Georgia Gkioxari, Piotr Dolla, Ross Girshick.
The system for document understanding successfully applies convolutional neural network, implementing automatic document processing, detecting the main concepts and the embedded elements. Based on the data analysis phase, identifying the main classes which represent the basic concepts of the document’s domain, the segments of the document image are annotated. We have experimented with several convolutional models, among them is Mask R-CNN.
 |
| Fig. 1. Mask R-CNN. source: original paper |
Object Detection
An object recognition algorithm identifies which objects are present in an image. It takes the entire image as an input and outputs class labels and class probabilities of objects present in that image. For example, a class label could be “cat” and the associated class probability could be 97%. The object detection methods add the location with coordinates of outputs bounding boxes as well and predict where on the image is the object.
Convolutional neural network for object detection classifies the objects and finds the location within the document, the methods determine where the regions of a concepts interest are, and the elements’ location within the detected regions. Annotation according to the required semantics may be different. We have chosen to label regions, following the predefined concepts, such as a person, experts, purpose, subject, etc. Also, the formatting elements, such as a box, table, grid, etc. The recognized regions represent complex concepts within the document, a data structure comprising different attributes. Along with our experiments, we encounter quite a few challenges, some of which are fonts, scale, quality, small objects and number of recognized objects. To overcome the various limitation, we have applied different image processing techniques.
The results are very good, though the task of document understanding requires knowledge objects and relations among them, it is not one of the designed purposes of CNN. We singled out the symbolic inference over relations as another step in document understanding solution.
Detectron, Mask R-CNN model outperformed the experiments with other architectures.
Detectron
Mask R-CNN
Mask R-CNN efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The architecture, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is a deep neural network targeted to solve the instance segmentation problem in computer vision. Identifies each object instance of each pixel for every known object within an image. It returns the object bounding boxes, classes and masks. There are two stages of Mask R-CNN. Firstly, it generates proposals about the regions where the object might be based on the input image. Secondly, it predicts the class of the object, refines the bounding box and generates a mask on the pixel level of the object based on the already existing proposals.
The most efficient for document processing was singled out to be Mask R-CNN. The achieved is 96% accuracy.
We have significantly reduced the implementation time with the IBM Visual Insights (prev. IBM PowerAI Vision), which is a software for computer vision and deep learning implementing the state-of-the-art CNN architectures.
FCN – Fully convolutional network
Mask R-CNN is a region-base convolutional neural network specifically Faster R-CNN, which has been improved by Fully convolution networks FCN branch. FCN is built only from locally connected layers, such as convolution, pooling and upsampling. No dense layer is used in this kind of architecture. This reduces the number of parameters and computation time. Also, the network can work regardless of the original image size, without requiring any fixed number of units at any stage.
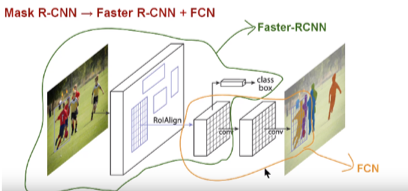 |
| Fig. 2. Mask R-CNN. Source: original papers |
Region-based convolutional neural network R-CNN
A group of architectures based on several different components, each of which is a network. The main components are the proposed region classification of classes R-CNN and are one among the first architectures used for object detection. In R-CNN the first stage is to construct different proposed regions. The proposed region is the area on the image which has a high probability of containing the object. To construct proposed regions, external region proposal methods like Selective Search is used.
Selective Search Algorithm:
1. Generate initial sub-segmentation, as to generate many candidate regions
2. Use the greedy algorithm to recursively combine similar regions into larger ones
3. Use the generated regions to produce the final candidate region proposals
In R-CNN, the input image is fed to the region proposal algorithm like selective search and perform CNN on each proposed region. The output of CNN is given to SVM’s for classification of objects detected. So, if there are 2000 proposed regions, the needed runs are 2000 CNN networks.
Fast R-CNN
This model is an improvement over R-CNN. It is 25x more effective than R-CNN. To reduce the overhead of multiple CNN networks in R-CNN, first, the input image is fed to CNN which gives an insight on the features in the image and then perform a selective search to get proposed regions.
RPN (Region Proposal Network)
RPN provides a time-effective way of generating region proposals/regions of interest. It is more effective than selection search used in R-CNN/Fast R-CNN. RPN ranks region boxes, called anchors and proposes the ones most likely containing objects. RPN has a classifier and a regressor. To generate proposals for the region where the object is, a small network is a slide over a convolutional feature map that is the output by the last convolutional layer. The anchor is the central point of the sliding window. The anchors are of different aspect-ratios and the proposals are based on significant Intersection-over-union overlap with a ground truth box. RPN is an algorithm which needs to be trained and has defined loss function.
Faster R-CNN
Faster R-CNN is an improvement over Fast R-CNN where, RPN is used as proposed region generator instead of selective search, Faster R-CNN is a combination of Fast R-CNN and RPN. The first stage is to prepare the features in the respective map and then suggests coordinates of the assumed location of the site. The proposed regions are given to a classifier for object classification. Faster R-CNN is a highly effective approach for object detection. It is 250x more effective than R-CNN.
From the group of architectures, we have experimented with Faster R-CNN, in the context of the document type for sick leave and it is not so accurate in determining the boundaries of the object and cannot recognize small objects with enough accuracy.
| Fig. 3. R-CNN, Fast R-CNN, Faster R-CNN. Source: original paper |
YOLO – You only look once
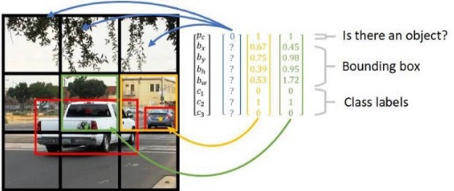
One of the fastest CNN, working in real-time. It is highly efficient because of not repeating a segment of the picture looking for different objects. The algorithm is not optimized for accuracy, but for time. Not effective enough to be able to recognize many small objects and full overlapping elements. Some elements in the document sample for sick leave are too small for this type of network.
 |
|
Fig.4. YOLO divides up the image into a grid of 13 by 13 cells: Each of these cells is responsible for predicting 5 bounding boxes. A bounding box describes the rectangle that encloses an object. YOLO also outputs a confidence score that tells us how certain it is that the predicted bounding box actually encloses some object |
References
1. Y. LeCun, P.Hafnner, L.Bottou, Y.Bengio 1998. Object Recognition with Gradient-based Learning
2. K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 93-202, 1980.
3. S. Ren, K. He, R. Girshick, J. Sun . Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
4. R.Girshick, J.Donahue , T. Darrell , J.Malik Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
5. R. Girshick, Fast R-CNN, in IEEE International Conference on Computer Vision (ICCV), 2015.
6. K. He, G. Gkioxari, P. Dollár, R. Girshick . Mask R-CNN arXiv preprint arXiv:1703.06870
J. Redmon, S. Divvala, R. Girshick, A. Farhadi. You only look once: Unified, real-time object detection Proceedings of the IEEE conference on computer vision and pattern, 779-78
About the author
Kristina Arnaoudova, PhD, AI Lab manager at IBS Bulgaria
Kristina is an IT professional with 15+ years of experience in customer & business relationship management, IT service management and software development, specialized in financial services. Nowadays, Kristina is deeply into AI and Data Science research and development as a leader at IBS AI Lab and lecturer for AI at Sofia University.






IBS (Email Application Registration)
Actions